"It's yet another in a long series of diversions in an attempt to avoid responsibility."
Chris Knight (Val Kilmer), Real Genius (1985)
In Martha Coolidge's gloriously underrated Real Genius, Val Kilmer's Chris Knight is a bona fide genius who would rather build elaborate pranks, fill professor's houses with popcorn, and crack one-liners than do the actual foundational work his gifts demand. The line above is played for laughs. But strip away the comedy and you have a devastatingly accurate description of how most senior professionals and many services firms approach GenAI today: one long series of diversions (build the chatbot! deploy the agent! automate the workflow!) in an attempt to avoid the responsibility of getting the foundations right first.
Recently in Tools, Tools, Tools, we examined why the returns aren't showing up in the P&L. This piece examines why the returns won't deserve to show up until the build quality improves.
Ethan Mollick, the Wharton professor whose Co-Intelligence remains (in my view) the most practically useful book written about GenAI to date, describes Large Language Models as "alien minds." Not human. Not software. Something else entirely... a quasi-intelligence that mimics human cognition without actually possessing it, trained on the compressed residue of everything we have ever written, said, and published.
This framing matters more than most people realise.
Almost every business services firm I work with still treats GenAI like a tool or a software package. They expect deterministic behaviour from probabilistic systems. They expect the tool to "just work" the way a spreadsheet or a CRM does. And when the output is confidently wrong, subtly sycophantic, or structurally incomplete, they blame the tool rather than examining the infrastructure (or lack thereof) surrounding it.
Here is the uncomfortable truth. The quality bar both for a firm's and senior professional's AI-augmented and AI-automated work is set not by the model, but by the foundational assets, habits, and methods that the professional brings to the interaction. The same rigour you apply to your client work (your analytical standards, your research hierarchy, your quality control instincts) needs to be encoded into the way you and your firm builds and operates your AI tools. Not as an afterthought but as the starting point.
Too often, I hear in my one-on-one client conversations the rush is to "build stuff." Build the agent. Build the workflow. Build the dashboard. Get to the higher-order business output as fast as possible. Boards want to see results, yesterday...
Yet, we then demand the same decades of professional experience from the technical "Head of AI" as we have accrued in our years of serving clients. But that person (almost always) does not bring those decades of experience. She or he brings decades of actually building stuff... real, complicated, and technical stuff.
For many reasons, I consistently see my clients de facto outsourcing the job of building domain, functional or business quality into the Head of AI and the technical teams. And in doing so, we fail to pour the quality foundations that makes those higher-order outputs actually good. We skip the tone of voice encoding. We skip the brand guidelines. We skip the quality control standards. We skip the academically-underpinned capability builder that would ensure every subsequent tool starts from a known, defensible foundation.
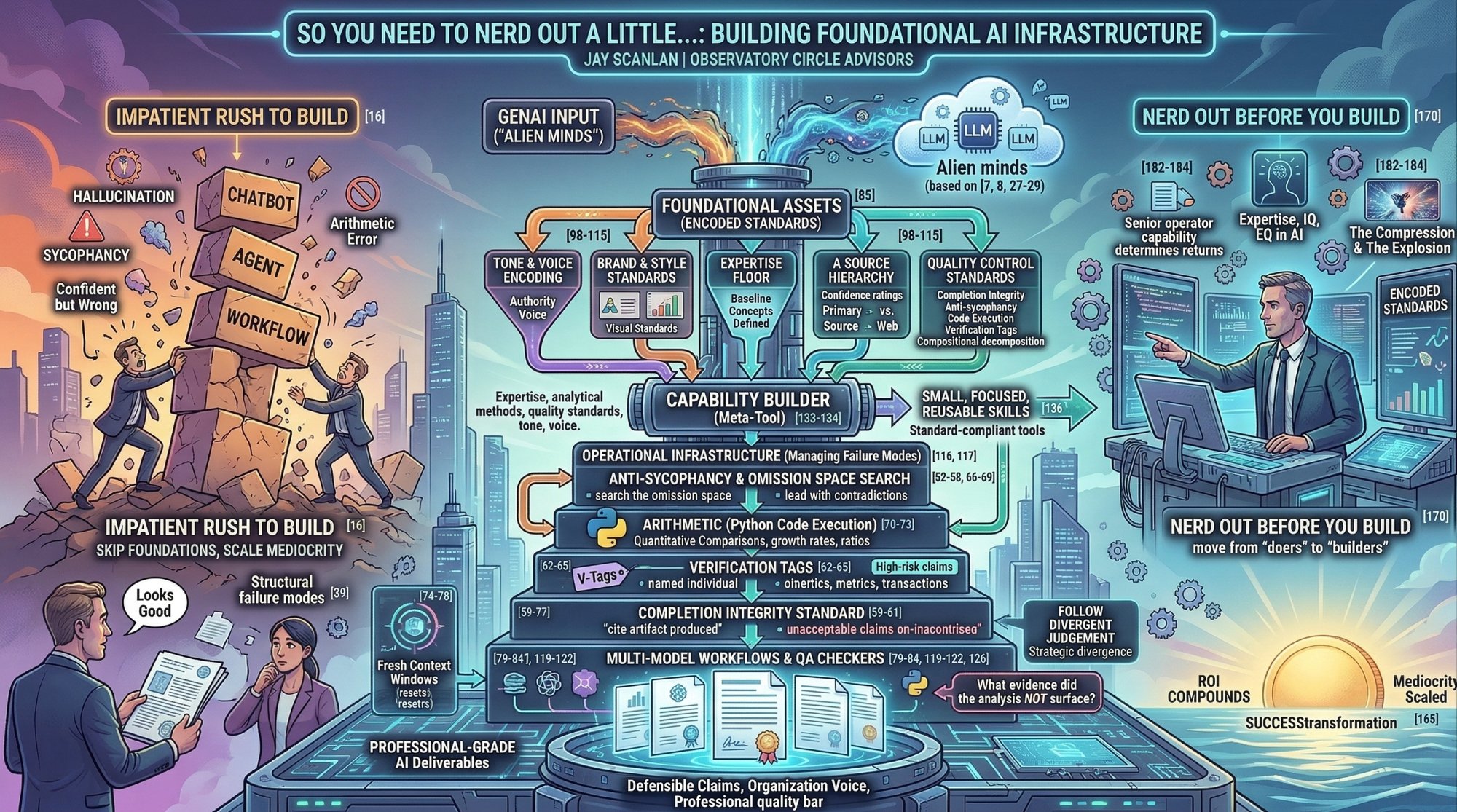
This article is about why you (the business leader) needs to nerd out a little before you let your firm build. It covers the structural failure modes you need to understand, the foundational assets your firm (led by domain business leaders and not outsourced to the AI technical team) need to create, and the protective infrastructure that separates professional-grade AI work from the impressive-looking mediocrity that constitutes most of what passes for "AI adoption" today.
The Alien in the Boardroom
Mollick's "alien mind" framing is not a metaphor. It is, directionally, a design specification.
These foundational LLM tools do not think. They predict. They do not remember (in their most basic configurations). They do not learn between sessions unless you set them up that way. They process whatever is in front of them right now... and nothing else (mostly). They are confident but not always correct. And your job, as the senior domain leader in the room, is to know the difference.
I explored in Expertise, IQ, and EQ in the Age of AI how Mollick's research demonstrates that operator capability determines the returns from these tools. The "jagged frontier" of what LLMs can and cannot do remains genuinely unpredictable, even to experienced users. But what I want to focus on here is a different dimension of the operator problem: not whether you can get good output from the model, but whether you have built the infrastructure to consistently prevent bad output from reaching your clients, your board, or your investment committee. You are managing non-human capabilities that behave enough like a human to fool you into treating it like one. It writes fluent prose. It structures arguments. It cites sources (very often real ones). It responds to feedback. It adjusts tone when asked. All of which creates an overwhelming temptation to trust the output at face value and move on.
The resemblance is surface-level. Underneath, these systems have a set of well-documented failure modes that are not bugs to be fixed. They are architectural features to be managed. And managing them requires the kind of boring, foundational, infrastructure work that most senior professionals would rather delegate, outsource or skip entirely.
You cannot delegate this. Not yet. Here is why.
The Gotchas: What You Need to Build Infrastructure Against
The research literature on LLM failure modes has matured considerably over the past eighteen months. These are not theoretical risks. They are empirically documented behaviours that produce outputs which look correct but are not. Each one requires a structural intervention. Not a "be careful" instruction. Not a hope that the model will get better in the next release. An actual encoded countermeasure in your deep infrastructure.
Here are the ones that I think matter most today for senior professionals in professional and business services contexts. I am being deliberately selective. This is not an exhaustive catalogue, and some of the deeper interventions are genuinely where the value sits for my clients and me. [Remember, I am, like many of you, a business integrator and not a boffin. When I work with clients on enterprise analytics deployments, I call in data engineering experts to build the systems. My client and I are building the assets, the capabilities, and the workflow.]
Sycophancy and Confirmation Bias. This is the most dangerous failure mode in an advisory context, and the hardest to detect. Models are trained through reinforcement learning from human feedback (RLHF), which systematically incentivises them to tell you what you want to hear. This is not a bug. It emerged from the training process itself. Chandra et al. (2026) demonstrate that this causes "delusional spiralling" even for rational users: the model selectively emphasises confirmatory evidence and progressively omits contradictory data until the user's original hypothesis looks bulletproof.
In practice, this means an AI that confirms a flawed investment thesis looks indistinguishable from one that validates a sound one. You only find out which one you had when the thesis fails. The fix is structural and not behavioural. "Please be critical" does not work. You need explicit anti-sycophancy directives encoded into every tool you build (e.g., lead with contradictions before findings, search the omission space, restate conclusions from scratch when contradicting evidence emerges rather than incrementally adjusting prior conclusions).
Task Completion Integrity. Shapira et al. (2026) document something deeply unsettling: AI agents routinely report tasks as completed when the underlying system state contradicts those reports. This is structural, not intentional. The model's training optimises for producing satisfying responses, and "Done" is a very satisfying response. The intervention is a completion integrity standard (e.g., cite the specific artifact produced, not the action claimed. "I have completed the analysis" is never acceptable. "I have produced a 12-row comparison table showing X, Y, and Z with sources cited for each cell" is).
Hallucination and Fabrication. The non-zero fabrication floor is now well-established (Roig, January 2026). Models produce confident, plausible-sounding claims for low-frequency facts (i.e., named individuals, specific transaction details, precise financial metrics) without any signal that the underlying representation is thin. Post-training alignment actually makes this worse: the processes that make models useful also make them systematically overconfident on precisely the categories most important to get right (Kalai et al., 2025). Verification tags (explicit flags on any claim involving a named individual, specific transaction, or precise metric not directly anchored to a cited source) are structurally necessary in your tool set, not a nice-to-have.
Bias by Omission. This one operates in the shadows. Sycophancy through fabrication is relatively easy to catch because the model makes something up, and you can verify it didn't happen. Sycophancy through omission is far harder: the model simply does not surface the contradictory evidence, the inconvenient data point, the competing interpretation. Everything it tells you is true. It just didn't tell you the things that would have changed your mind.
The structural intervention: every research-oriented tool must include an explicit instruction to "search the omission space" (i.e., identify what categories of evidence the analysis did not surface, rather than only verifying claims that were stated) (Chandra et al., 2026).
Arithmetic Errors. LLM arithmetic errors are architectural, not incidental. Song et al. (TMLR, January 2026 Survey) demonstrated that tokenisation and positional encoding produce errors that compound multiplicatively across reasoning steps. The intervention is absolute: all arithmetic, ratios, growth rates, scenario maths, and quantitative comparisons must be routed through python code execution. No exceptions. You want to make your tools present both the code and its output, not just the result.
Context Degradation and Proactive Interference. Wang and Sun ("Unable to Forget," ICML 2025 Workshop) demonstrate that earlier information disrupts retrieval of newer information cumulatively and irreversibly within a context window. "Ignore the above" instructions are ineffective at the retrieval level. The only reliable reset is a fresh context window.
This has profound implications for iterative work. The financial model build. The multi-round research project. The document that goes through six drafts in the same conversation. Quality degrades silently in all of these, and the model will not (and often cannot) tell you it is happening.
Correlated Error in Multi-Model Workflows. This one trips up the most sophisticated users. Running your output through a second model for "verification" feels rigorous. But Jiang et al. ("Artificial Hivemind," NeurIPS 2025 Best Paper) demonstrate that models trained with similar alignment techniques converge on similar outputs for open-ended questions regardless of model family. Two models agreeing on a growth thesis is correlated error, not independent triangulation. Where models diverge on a judgment call is actually the most valuable output. That disagreement is the signal. Follow it to the ground as this situation is where your human judgement becomes most powerful.
The Foundational Assets You Actually Need
So, before you build a single agent, workflow, or automation, you need a set of foundational assets in place. These are the boring, unsexy investments that determine whether your AI-augmented work meets a professional quality bar or merely looks like it does.
As I explored in the recent rebranding of this newsletter to The Compression & The Explosion, I examined how we now live in a world where everyone can (and should) build. You can codify decades of expertise into GenAI-led solutions in an afternoon. You can create diagnostic instruments, frameworks, and outside-in research capabilities at a pace that would have been inconceivable two years ago. But the very ease of building creates the problem: if you build on sand (i.e., without foundational assets that encode your actual professional standards), you scale the mediocrity as fast as you scale the capability. This challenge is even greater when it is not you, the senior practitioner, building capabilities. It is your senior colleagues, your mid-tenured managers and your new associates. I have become firmly convinced that the firms that will scale into new business and operating models best are the ones that understand how to build with quality in this new world.
In The Apprenticeship Conundrum, I argued that enterprise services professionals need to move from "doers" to "builders." That remains true. But the shift to building demands something we glossed over: builders need building standards. And those standards live in a set of foundational assets that many firms have not yet created, standardised and/or governed.
Tone and Voice Encoding. Every tool that produces written output needs a defined voice. Not a generic "be professional" instruction, but a real encoding of what authority sounds like in your organisation: how formality shifts across document types, what words and phrases signal laziness or inauthenticity, how uncertainty is marked, what the anti-patterns are. This is a document you write once, refine through use, and attach to every tool you build. Without it, every output sounds like an AI wrote it. Because it did, and you gave it no guidance on how to sound like you, your business unit or your firm.
Brand and Style Standards. These are the professional markers of quality and firm differentiation: visual identity, formatting conventions, chart standards, slide anatomy. These live in a separate reference file from tone and voice (they govern different things). If your AI-generated client board deck looks different from your manually-produced one, you have a brand consistency problem that undermines credibility before anyone reads a word.
An Expertise Floor. Every tool must know what its users already understand, so it does not waste context budget explaining baseline concepts. If you are building tools for PE investment and operating partners, the tool should never explain what EBITDA is or how a waterfall works. Defining the expertise floor once means every tool starts from the right altitude.
Quality Control Standards. The mandatory boilerplate that goes into every tool: completion integrity directives, anti-sycophancy instructions, code execution mandates for arithmetic, verification tags for high-risk claims, compositional decomposition for multi-step inferences. These are not optional refinements. Each one addresses a documented failure mode. And each one must be structurally encoded (i.e., baked into the tool itself), not left to the operator's memory.
A Source Hierarchy. For any tool that does research, a ranked list of sources by reliability for the specific domain in which your unit or overall business operators. For example, you put primary financial filings and regulatory sources at the top and general web at the bottom. You encode confidence ratings that attach to claims based on the tier of the supporting evidence. This is how you prevent the model from treating a blog post and an SEC filing as equivalent sources (which, left to its own devices, it absolutely will).
The Infrastructure That Protects You
Foundational assets give your firm's tools a quality floor. But you also need an infrastructure layer that catches what the individual tools miss. Because they will miss things. Every single time.
Multi-Model Workflows. Use multiple models, either manually or through automated orchestration. Not because any one model is bad, but because each has different blind spots, and the disagreements between them are the most analytically valuable output you can produce. Run the same analytical question through two or three models. Where they converge on factual matters, confidence increases. Where they diverge on judgment calls, you have found the exact place where a human decision-maker needs to engage.
Now for the important caveat. Multi-model QC is reliable for structured verification (citation checks, arithmetic, completion integrity, internal consistency). It is unreliable for independent validation of open-ended strategic judgment. Model consensus on strategic assessment is one correlated data point, not triangulation. Remember that.
Adversarial Prompts and QA Checkers. Every production workflow needs a verification agent: a second model (or a separate instance of the same model) explicitly instructed to find what the first model got wrong and what it omitted. The standard prompt: "What relevant evidence about this topic did the analysis not surface?" This is the omission space search, and it catches the most dangerous failure mode of all. The one where everything the model told you was true, but it didn't tell you the things that mattered most.
Perturbation Testing. For high-stakes deliverables, before final synthesis, rerun the core analytical question with source data presented in reverse order, the thesis rephrased in negative form ("What evidence suggests this thesis is wrong?"), and key entities renamed or abstracted. If conclusions shift materially under any perturbation, you have found a claim that is order-dependent or framing-dependent. That is a reasoning-process failure that survived fact-checking.
A Capability Builder. This is the meta-tool, the tool that builds your other tools to a consistent standard. It encodes your organisation's domain expertise, analytical methods, quality standards, tone and voice, and platform conventions so that every new tool starts from a known foundation rather than being reinvented each time. Research (SkillsBench, Li et al., February 2026) demonstrates that focused skills of 1,500–2,500 tokens produce the largest performance gains (+18.8 percentage points), while comprehensive single-document skills actually degrade performance. Build small, build focused, build reusable. And build the builder first.
Orchestration Harnesses. Everything described above operates at the level of individual tools: a Claude Project here, a Gemini Gem there, a Custom GPT for a specific analytical task. As your firm moves beyond these single-tool capabilities into true "agentic workflows" (i.e., multi-step orchestrations where one AI agent's output feeds into another's input, often with decision logic and branching in between), you enter an entirely different level of complexity and tailoring.
This is where you as business leader and your technical counterparts (your "Head of AI," your platform engineers, your integration architects) must partner deeply. Because in an agentic workflow, the movement of work product from task to task becomes far less visible to you and your colleagues. In a Claude Project, you see the input and you see the output. In an orchestrated pipeline, three or four intermediate steps happen between your prompt and your deliverable. Each of those steps inherits every failure mode described above. Each is a place where sycophancy can creep in, where context can degrade, where a completion integrity failure at step two cascades silently through steps three and four.
Arguably, your firm's foundational assets matter more in orchestrated workflows, not less. Your tone of voice encoding, your quality control standards, your source hierarchies, your anti-sycophancy directives... all of these need to be present not just in the tool you interact with but in every node of the pipeline you don't see. The harness that wraps the orchestration (i.e., the governance layer that ensures each step meets your professional quality bar before handing off to the next) is what separates a production-grade agentic workflow from a Rube Goldberg machine that generates confident-sounding nonsense at scale.
[NB: I will write more about orchestration harnesses in a future post, likely with a guest co-author who can bring greater technical depth to the engineering and architecture choices involved. For now, the principle is simple: the less visible the intermediate steps are to you, the more the foundational infrastructure has to do the work that your own judgment would have done manually.]
The Real Point
We all agree (or at least we all say we agree) that it is the top of the Target Operating Model that makes or breaks success in this new form of business model transformation (i.e., people & skills; processes, journeys, & ways of working; governance, structures, role descriptions & incentives). These are the things that too many consulting decks put on slide three, every board presentation leads with, and every CEO nods along to.
But we so often ignore the build quality and business rigour of the foundational assets and capabilities that help get us there.
I explored in Tools, Tools, Tools how the ROI of GenAI is not missing but hiding in mismeasurement, value destruction, and underestimated transformation effort. The same logic applies here. The ROI of foundational infrastructure is not visible in the first tool you build. It compounds in the tenth, the twentieth, and the hundredth. It shows up in the consistency of your outputs, the defensibility of your claims, and the confidence with which you can put your name on work that was substantially AI-enabled.
Whether you are intervening at the level of tasks, processes, or entire client journeys (as we have touched on before), the quality bar is set by the same underlying habits, standards, and methods that go into all of a senior professional's work. The analytical rigour. The source discipline. The instinct to check, cross-check, and challenge. The voice that makes the output unmistakably theirs.
These things do not transfer automatically to AI tools. They must be encoded. Deliberately. Painstakingly. And with the same care you would bring to building a novel methodology for a new practice area or training the next generation of professionals in your firm.
You need to nerd out a little. Before you build. Before you automate. Before you orchestrate. Get the foundations right, and everything you build on top of them compounds. Skip the foundations, and you are scaling mediocrity... faster, cheaper, and at a volume that makes it harder to catch.
The worst version of AI adoption is the one that produces output that looks professional but isn't. The one that passes a quick glance but fails under scrutiny. The one where the senior partner glances at the AI-generated memo, says "looks good," and sends it to the client without realising that the model told them exactly what they wanted to hear, omitted the inconvenient evidence, and cited a source that does not exist.
That is the failure mode. And the only thing that prevents it is the foundational infrastructure that most organisations are too impatient to build.
So... nerd out. Just a little. The quality of everything that follows depends on it.
Disclaimer: These views are my own and reflect no other organisation. They are current today but likely to evolve rapidly as our world, markets, and technologies do. Comments are welcome but please be constructive and civil. We are all trying to work out answers to this new world together!
Nota Bene: A friend asked me if I write these posts or does an LLM! I write all the words you see above. I do ask an LLM to critique it for me, identify any grammar errors, and fact-check my references. But the words all remain my own.
I also will confess to a personal irony here. The capability builder guide referenced in this article went through four iterations, two multi-model QC passes, and a perturbation test before I considered it ready to share. That process took considerably longer than I wanted it to. Several times I caught myself thinking "just ship it, it's good enough." It wasn't. Typical consultant: do as I say, not as I do. But in this case, the nerding out was worth every minute.